
”k-means 肘部法 聚类优化 聚类“ 的搜索结果

“ k-Means聚类背后的想法是获取一堆数据并确定数据中是否存在任何自然聚类(相关对象的组)。 k-Means算法是所谓的无监督学习算法。 我们事先不知道数据中存在什么模式-它没有形式分类-但我们想知道是否可以将数据...
数据预处理2.1 为向量化表示进行前处理2.2 TF-IDF2.3 Stemming2.4 Tokenizing2.5 使用停用词、stemming 和自定义的 tokenizing 进行 TFIDF 向量化3 K-Means 聚类3.1 使用手肘法选择聚类簇的数量3.2 Clusters 等于 ...

K-means是一种常用的聚类算法,用于将数据集中的观测点分为不同的群组或簇。聚类是一种无监督学习方法,其目标是发现数据中隐藏的结构,将相似的数据点划分为同一组,同时将不相似的数据点划分为不同的组。
时,我们通常会先对数据集进行聚类。这涉及将聚类算法应用于将数据分组为两个或三个独立的群组。一旦我们有了这些群组,我们就可以对每个群组应用。


一、聚类分析 1.1 聚类分析 聚类: 把相似数据并成一组(group)的方法。‘物以类聚,人以群分’ 不需要类别标注的算法,直接从数据中学习模式 所以,聚类是一种 数据探索 的分析方法,他帮助我们在大量数据中...
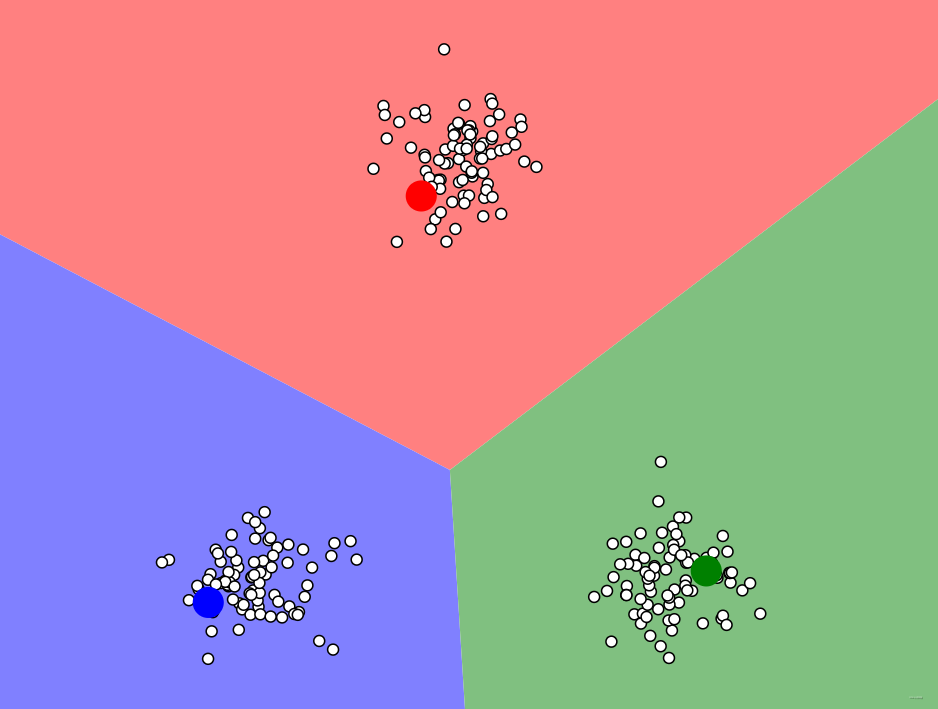
实验:K-means实现无监督聚类 1 定义和调用更新每个样本所属聚类,聚类中心更新,初始化聚类中心的参数 2 定义Kmeans算法获得最终的聚类中心和样本所属聚类索引 3 绘制各个聚类的图 4 定义评价函数--即任意一点所在...

聚类的思想 所谓聚类算法是指将一堆没有标签的数据自动划分成几类的方法,...K-means方法是聚类中的经典算法,数据挖掘十大经典算法之一;算法接受参数k,然后将事先输入的n个数据对象划分为k个聚类以便使得所获得的聚类






机器学习方法主要分为监督学习方法和非监督学习方法两种。监督学习方法是在样本类别标签已知的条件下进行的,可以统计出各类训练样本的概率分布、特征空间分布区域等描述量,然后利用这些...聚类分析概述K-means 算法。
机器学习算法的分类 一、什么是聚类分析 物以类聚,人以群分 二、相似度与距离度量
1 K-means聚类算法 2 常见面试题 2.1 简述K-means聚类算法的执行过程 2.2 分析K-means聚类算法中的K如何取值 2.3 K-means算法有哪些优缺点?有哪些改进的模型? 0 聚类算法概述 聚类算法又叫做“无监督分类”,其...
K_Means算法(K_均值算法)就是无监督算法之一 1.原理 对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。 数据表达式: 假设簇划分为(C1,...




1. 聚类模型的概念 “物以类聚,人以群分”,所谓的聚类,就是将样本划分为由类似的对象组成的多个类的过程。 聚类后,我们可以更加...2. K-means聚类算法(K均值) 2.1 步骤 指定需要划分的簇[cù]的个数K值(...
k均值K-means算法案例,包括K=2和肘部法则及图形展示
推荐文章
- GPT-ArcGIS数据处理、空间分析、可视化及多案例综合应用
- 在Debian 10上安装MySQL_debian mysql安装-程序员宅基地
- edge 此项内容已下载并添加到 Chrome 中。_一个小扩展,解决Chrome长期以来的大痛点...-程序员宅基地
- vue js 点击按钮为当前获得焦点的输入框输入值_vue获得当前获得焦点的元素-程序员宅基地
- Android 资源文件中@、@android:type、@*、?、@+含义和区别_@android @*android-程序员宅基地
- python中的正则表达式是干嘛的_Python中正则表达式介绍-程序员宅基地
- GeoGeo多线程_geo 多线程-程序员宅基地
- phpstudy的Apache无法启动_phpstudy apache无-程序员宅基地
- 数据泵导出出现ORA-31617错误-程序员宅基地
- java基础巩固-宇宙第一AiYWM:为了维持生计,两年多实验室项目经验之分层总结和其他后端开发好的习惯~整起_java两年经验项目-程序员宅基地